Inteligecia artificial para el sector turístico

Inteligencia Artificial encara al sector turístico. Reconocimiento de imágenes
El modelo anterior tenía aproximadamente 13.000 imágenes y tardó unas 70h en procesar cada época (una época es una única pasada por todo el dataset completo de imágenes). Consistía en 47 características diferentes (piscina pública, privada, jardín, barbacoa, habitación, cocina, sala de estar, ....). Estas imágenes se obtuvieron de unos datasets públicos en internet y se tuvieron que filtrar préviamente, ya que aparecían imágenes que no eran útiles para nuestro objetivo. Para ir bien, habría que realizar unas cuantas épocas y así optimizar el modelo. Con máquinas actuales basadas en cálculos a través de las GPU'S es más rápido, pero como me gusta reaprovechar el material y no tirarlo, he aprovechado una máquina del 2009 para que vuelva a trabajar en los tiempos de hoy. Solo dispone de un procesador Pentium Dual Core y no utiliza las últimas instrucciones optimizadas para Deep Learning (como las últimas compilaciones de Tensorflow que utilizan SSE4, instrucciones de procesador AVX, etc), pero.... servirá ^_^'.
El resultado de la clasificación de las primeras 13.000 imágenes genéricas ha sido bastante bueno. Se ha utilizado para clasificar las más de 22.000 imágenes de la empresa, con una tasa de acierto de cerca del 80%. Ya os avanzo que mi intención es incrementar esta tasa de acierto, realizando un segundo paso explicado a continuación.
El segundo paso que nos encontramos ahora es utilizar este dataset clasificado por nosotros mismos para que el sistema aprenda mejor. Para ello se ha utilizado algunas imágenes del dataset anterior que funcionaban muy bien (piscina, cocina, terraza, ...) y se han descartado otras que 'despistaban' al sistema ya sea por la falta de imágenes o por las características genéricas que no coincidían (piscina cerrada, aire acondicionado, chimenea, ....).
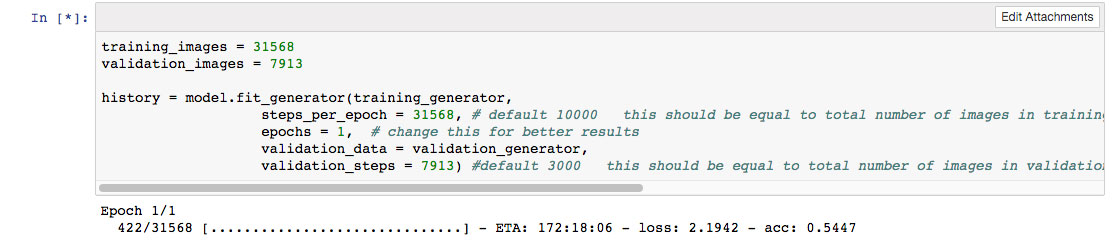
El nuevo dataset consta ahora de 39.500 imágenes. Se utilizarán 31.500 imágenes para realizar el Train y casi 8.000 para el dataset de Validación. Se recomienda utilizar aproximadamente un 20% del global de imágenes para el Test y validación.
El nuevo número de características (neuronas de salida) se ha reducido de 47 a 29. Este nuevo dataset englobará todas las características genéricas y más adelante se realizará un deep learning con datasets de imágenes concretas (piscina comunitaria y privada, habitación genérica y de niños, o con cuna, ....) Se pretende que el primer modelo haga una criba genérica y posteriormente los otros modelos especializados se encarguen de desentrañar las características más concretas de ese tipo de imágenes.
El nuevo dataset genérico tardará unas 172h en completarse. El anterior tardaba 70h. Aunque este nuevo tenga menos neuronas de salida, contiene muchísimas más imágenes.
Como curiosidad, se me pasó por la cabeza enviar al modelo dibujos realizados a mano. Escogí 12 diferentes de playa. Eran dibujos de líneas, otros coloreados y otros pintados como un cuadro, digamos. Lo curioso es que todos los dibujos de líneas, para el sistema eran GIMNASIOS. Los coloridos eran HABITACIONES PARA NIÑOS. El resto lo acertó bastante bien. Tiene lógica. El sistema nunca aprendió dibujos, si no, fotos, por lo que las líneas de los dibujos le indicaban que debían de ser los aparatos de un gimnasio, los dibujos coloreados le indicaban que eran habitaciones de niños, donde suelen abundar este tipo de objetos. Curioso, ¿no?
Ahora paciencia, y ya os contaré ;D



Comentarios